Apprentissage par renforcement
Programme où un agent doit défendre sa base face à un intrus qui empreinte toujours le même chemin.
Inspiration du code Maze.py pour faire ce code
1. Initialisation des paramètres
2. Définition des actions
3. Ajout des fonctions
4. Création de la boucle d'apprentissage
5. Visualisations
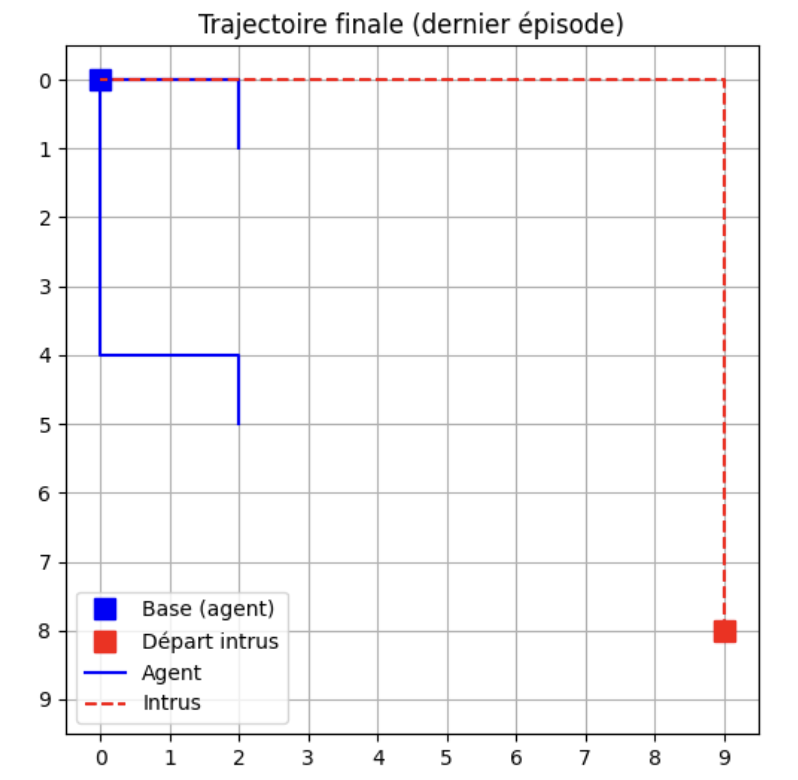
Visualisation des chemins empreter par l'agent
Lorsque Epsilon est proche de 0 alors l'intrus sera intercepté dans la majortié des épisodes
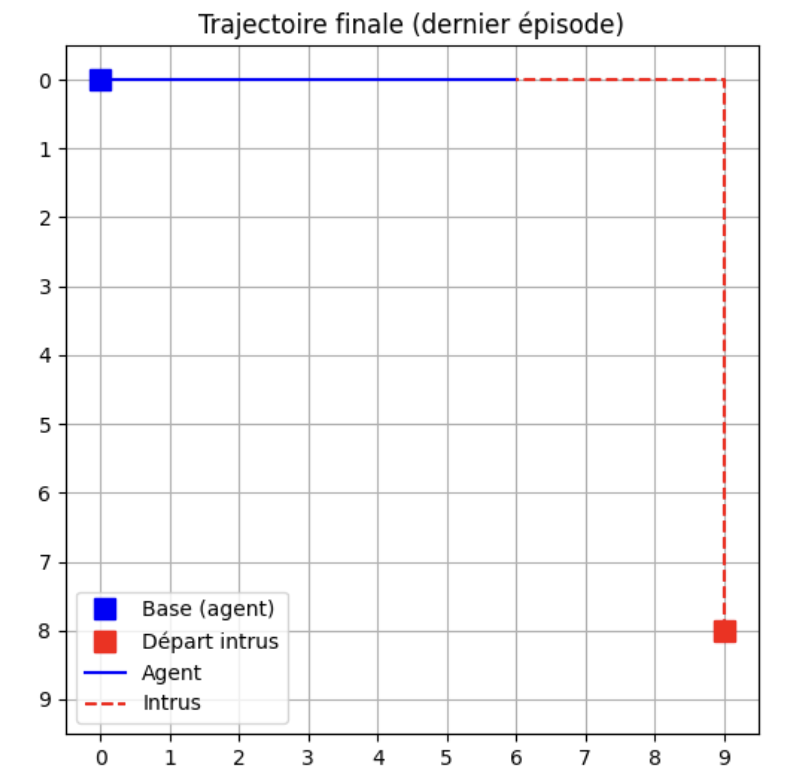
Lorsque Epsilon est proche de 1 alors l'agent va tester d'autres chemins donc ira pas intercepter l'intrus